


Yapay zeka teknolojileri gün geçtikçe hayatımızda ve kullandığımız bilgi bağlantı araçlarında bir epey kıymet arz etmeye başlıyor. Objelerin internetinin yaygınlaşması ve çiplerin küçülmesi sayesinde neredeyse 2-3 adet bozuk para boyutunda devre kartları kullanılarak yapılan akıllı aygıtlar görmeye başladık.
Bu yenilikçi projeler ve aygıtlar sayesinde makineler artık beşerlerle evvelce hiç olmadığı kadar etkileşime giriyor. Bu da makinelerle insanların anlaşabilmeleri ve komutları muvaffakiyetle yerine getirebilmesi için farklı bir yapay zeka cinsinin gelişmesinin önünü açıyor.
Bu yazımızda yıllardır makine tahsili ve yapay zeka alanında çalışmalar yapan GPU üreticisi NVIDIA’nın bu alanda yazmış olduğu makaleden faydalanarak sizleri “Conversational AI” yani “Diyalog Bazlı Yapay Zeka” hakkında bilgilendirmeye çalışacağız.
İddia edebileceğiniz üzere beşerler ile makineler ortasındaki etkileşimin arttırılması hedefleniyorsa, makineler ve beşerler ortasında kaliteli bir diyalog yapısının kurulması hayli kıymetlidir. Makine üzere programlanan bir aygıt ile onu kullanan beşerler ortasında pak ve kulağa doğal gelen bir mutabakat yolunun geliştirilmesi tam olarak da “Conversational AI” kısmının ilgilendiği şey.
Bunun için de geliştiriciler yapay zeka teknikleri ile birtakım konuşma zekaları geliştirmeye başladılar. Ama şu ana kadar geliştirilmiş olan gerçek vakitli konuşma uygulamalarının gerisinde yatan lisan sürece maksatlı hudut ağlarını geliştiren kimseler birçok talihsizlikle karşılaştı. Bu talihsizliklerden en büyüğü cevabı verecek olan yapay zekanın, cevabı süratlice karşılamak için mecburen kaliteden ödün vermesiydi. Kaliteli bir karşılık alınmak istendiğinde sonuç kestirim edebileceğiniz üzere hayli uzun bekleme müddetlerinden ibaret oldu.
Aslında bunun en temel nedeni insanların kullandığı lisanın bilgisayarlara nazaran epey karmaşık olması. Bizlerin kullandığı en ufak bir sözcük, yaptığımız en ufak bir ima bile birbiriyle temaslı biçimde ağzımızdan çıkmakta. Ayrıyeten insan konuşması çeşitli özneler, objeler ve bağlamlar içerdiğinden durumu yapay zekalar açısından daha anlaşılmaz hale getirmekte. Atasözlerinden tutun da, latifeler ve söz oyunlarına kadar beşerler ekseriyetle bir incelik, sistem içerisinde konuşurlar. Verdiğimiz her cevap ekseriyetle sonucu anında takip edecek halde olur. Örneğin arkadaşlarımızla söz bulmaca oyunu oynarken, sözler daha söylenmeden çabucak evvel karşımızdakinin ne söyleyeceğini iddia edebiliyoruz.
İşte 2021 yılında hala yapay zekalarla beşerler ortasında tam manasıyla düzgün bir irtibat kuralamamasının ana nedenlerinden biri bu. Konuşurken kullandığımız lisan yalnızca sözlerin bir ortaya gelmesinden oluşan cümlelerden ibaret olmak yerine altında zımnî imalar da içerebiliyor. Yapay zeka geliştiricileri her geçen gün yeni lisan sürece motorları ve hudut ağları geliştirerek bunu aşmaya çalışıyor.

Conversational AI, beşerlerle onların anlayabileceği diyaloglar yoluyla bağlantı kurabilen ve insanların kullandığı bağlamlarla tabirleri yakalayarak akıllı cevaplar verebilmek için geliştirilen yapay zeka robotlarına yahut sesli asistanlara deniliyor.
Bu usul yapay zeka modelleri ziyadesiyle karmaşık yapılardır diyebiliriz. En büyük sorun şu ki bir yapay zeka modeli ne kadar büyük ve karmaşıksa kullanıcının sorduğu soruya o kadar geç karşılık verecektir. Saniyenin onda üçünden daha yüksek gecikmeler ekseriyetle bağlantısı anlamsız kılar, kulağa güzel gelmez.
NVIDIA’nın yapay zeka alanında yaptığı araştırma geliştirme süreçleri sonucunda NVIDIA GPU’lar yardımıyla diyaloğa dayalı AI geliştirirken, CUDA-X AI kitaplıkları ve son teknoloji lisan modelleri, ilgili yapay zeka modelinin saniyenin binde biri oranında çıkarım yapması için kullanılabilir. Ayrıyeten modelinizi optimize etmek için de bu teknolojilerden faydalanabilirsiniz. Bunun yapay zeka modellerinin karmaşık yapıları nedeniyle yaşanan yavaşlık sıkıntısını ortadan kaldırmak için epey kıymetli bir adım olduğu aşikar.
Bu üslup atılımlar sayesinde geliştiriciler artık şu ana kadarki en âlâ ve gelişmiş hudut ağlarını oluşturup kullanıma hazır hale getirebilir. Böylelikle konuşmaya dayalı insan-makine etkileşimi gayemize insanlık olarak daha fazla yaklaşmaktayız. GPU (Grafik Süreç Ünitesi -fazlasıyla süratli ve yüksek paralel süreç yeteneği nedeniyle) için optimize edilen lisan algılama modelleri, finansal hizmetler, sıhhat hizmetleri, perakende ve daha birçok dalda kullanılabilecek yapay zeka uygulamalarının geliştirilmesinde kullanılabilir. Böylelikle akıllı hoparlörler, irtibat sınırları ve gelişmiş dijital asistanlar yardımıyla hizmet bölümü farklı boyutlara varabilir.
Ayrıyeten yüksek kalitedeki akıllı diyaloğa sahip yapay zeka araçları sayesinde dalda yer alan kurum ve kuruluşlar, işletmeler müşterileriyle klasik bağlantı sistemlerinde uygulanması mümkün olmayan şahsileştirilmiş hizmetler yardımıyla her daim faal bir halde bağlantıda kalabilirler.
Çoklukla iki insan ortasında geçen doğal bir konuşma sürecinde cevaplar ortasında yaklaşık 300 milisaniye vardır. İnsanların yönelttiği soruya mantıklı bir karşılık bulabilmesi için yapay zekanın bundan daha kısa bir müddette karşılık vermesi gerekiyor. Karşıdaki yapay zekanın insanlara emsal etkileşim süreçlerini cevaplayabilmesi için çok katmanlı süreçlerin kesimi olarak bir düzine yahut kat kat fazla hudut ağına muhtaçlık duyması mümkündür. Bunların hepsi en geç 300 milisaniye içerisinde gerçekleşmek zorunda.
Bir yapay zekanın soruya yanıt vermesi için art planda ekseriyetle şunlar yaşanır:
- Kullanıcının konuşması metne dönüştürülür
- Dönüştürülen metnin/cümlenin manası kavranmaya çalışılır
- Cevap olarak verilebilecek en yeterli yanıt verilmeye sağlanılır
- Akabinde cevap özel bir metinden konuşma aracıyla insanlara ulaştırılır
Her bir modelin çalışması 10 milisaniyeden daha uzun sürerse reaksiyon çok yavaş olacağından, konuşma süreci doğallıktan uzak ve anlamsız seslerden ibaret bir hal alır. Bu da diyalog tabanlı bir yapay zeka geliştirirken asla istemeyeceğiniz bir şey.
Böylesi sıkı bir gecikme bedeline nazaran çalışmak zorunda olan geliştiriciler, mevcut lisan manaya araçlarını daha farklı biçimde kullanmak üzere ayarlamak mecburiyetinde kalabiliyor. Mesela yüksek kaliteli ve karmaşık bir yapay zeka modeli ses arayüzü kullanılmayacaksa gecikme değersiz olacağından bu model yazılı sohbet robotu olarak rahatlıkla kullanılabilir. Şayet model illa ses tabanlı işlerde kullanılacaksa, geliştiriciler gecikmenin az olduğu ancak nitelikli karşılıklardan mahrum lisan sürece modellerini kullanarak uygulamalar geliştirebilirler.
Lakin bu bahsettiklerimiz çoklukla bir diyalog tabanlı AI projesinde geliştirici olarak tercih etmeniz gereken en makus seçeneklerdir. Bunun yerine NVIDIA Jarvis üzere özel kütüphaneleri de durumu düzgünleştirmek ismine kullanabilirsiniz.
NVIDIA Jarvis, 300 milisaniye eşiğinin çok çok altında çalışabilen yüksek doğruluklu diyalog tabanlı yapay zekalar geliştiren yapay zeka uzmanlarına yönelik epey varlıklı bir kütüphane. Böylelikle geliştiriciler NVIDIA DGX sistemlerde 100.000 saatten fazla vakitte eğitilmiş son teknoloji yapay zeka modellerini kullanarak geliştirme sürecini iyileştirebilirler.
Ayrıyeten geliştiriciler, bu modellerdeki özel datalarda ince ayarlar yapmak için “Transfer Learning Toolkit” ile transfer tahsili prosedürü uygulayabilir. Bu stil modeller ve ince ayarlar sayesinde hizmet bölümü için tasarlanmış bir yapay zekada şirket jargonunu kullanmak mümkün hale geliyor. Böylelikle bu botlardan hizmet alan kullanıcı memnuniyeti oldukça artıyor.
Modeller NVIDIA tarafından geliştirilen yüksek performanslı kestirim SDK’sı TensorRT ile optimize edilebiliyor ayrıyeten data merkezlerinde çalışan ölçekli hizmetler halinde dağıtılabiliyor. Bu usullerin hepsi aygıtlarla insan etkileşimini arttırmak gayesiyle kullanılan görme yahut konuşma tabanlı yapay zeka uygulamaları oluşturmak için kullanılabilir. NVIDIA Jarvis, rastgele bir alanda daha evvelce yalnızca yapay zeka uzmanlarının deneyimleyebildiği teknolojileri kullanma imkanı sunuyor.
Kolay davet ağacı algoritmaları üzere ses arayüzlerinin kullanıldığı (örneğin “Yeni bir uçuş rezervasyonu yaptırmak için “rezervasyon” sözünü “söyleyin” gibisinden) sistemler süreç bazlıdır ve kullanıcıların daha evvel programlanmış bir dizi karşılıktan birini vermesini gerektirir. Bazen yalnızca bir insan temsilci, telefon ağacının sonunda incelikli bir soruyu anlayıp arayanın meselesini makul çözebilir.
Ancak günümüzde halihazırda piyasada olan sesli asistanlar bunun çok daha fazlasını yapabiliyor. Lakin milyarlarca parametre kullanmak yerine milyonlarca parametre kullanarak karmaşıklıktan uzak lisan modellerinden yararlanıyorlar. Bu yüzden yalnızca bir işi en sade haliyle söylediğiniz takdirde bunu algılayıp yanıtlayabiliyorlar. Bu şekil yapay zeka uygulamaları sorulan soruyu cevaplamadan evvel “bunu sizin için araştırmama müsaade verin”, “bunu bilmiyorum, katkıda bulunmak ister misiniz”, “geri bildirim yapar mısınız” formunda bildirimlerle konuşmayı maalesef bölebilmekte. Yahut daha yaygın görülen sesli asistan davranışı ise sorulan bir soruyu direkt web üzerinde aratmak. Böylelikle sorulan soruya uygulama tarafından sesli bir cevap verilmemiş olunuyor.
Gerçek bir diyalog tabanlı konuşma yapay zekası kelam mevzusuysa bunun çok daha ilerisine gidilmesi mümkün. Ülkü bir yapay konuşma zekası, bir kişinin tıbbi rapor sonuçlarını yahut banka hesap özetindeki sorgularını gerçek bir biçimde anlayıp yerine getirecek kadar karmaşık ve kusursuz, ayrıyeten anında cevap verebilecek kadar da süratli olmalıdır.
NVIDIA’nın başlığımızın konusu hakkında hazırlamış olduğu görüntüyü aşağıdan izleyebilirsiniz.
Bu şekil gerçek karşılıklar veren yapay zeka uygulamaları oluşturularak çeşitli bölümlerde kullanılmak üzere sesli asistanlar geliştirilebilir. Örneğin bir hastanın doktora gitmek için poliklinikten randevu alması yahut şeker hastasıysa şeker ölçüm pahalarını takip etmesini sağlayan yapay zekalar sıhhat kesimine hayli yarar sağlayabilir. Ayrıyeten bir paket bekleyen ama kendisine paketin uluşmadığını anlayıp üzülen birisine sesli yapay zeka tarafından açıklama yapılıp ek armağan çeki verilebilir. Özetle uzmanların amacı gerçek dünyada bir insan ile nasıl etkileşimdeysek yapay zekayla da birebir formda etkileşimde olmak.
Bu stil yapay konuşma zekalarına olan talepler oldukça artıyor. Geçmiş araştırmalara nazaran aramaların yaklaşık yüzde 50’si 2020 yılına kadar olan süreçte sesli olarak yürütülecek deniliyordu. Ayrıyeten 2023’e kadar etkin kullanımda yaklaşık 8 milyar sesli asistanın olması geleceğe dair yapılan iddialar ortasında.
BERT (Bidirectional Encoder Representations from Transformers) geçen sene piyasaya çıktığında bizlerin konuştuğu doğal lisanı anlamak için geliştirilen en son teknolojiyi belirleyen büyük, tıpkı vakitte hesaplama açısından da epey ağır bir yapay zeka modeliydi. Yapılacak ince ayarlar sonrası okuduğunu manaya, his tahlili, soru-cevap üzere çeşitli gayelerle BERT faal biçimde kullanılabilmekte.
3.3 milyar sözden oluşan devasa bir İngilizce metin külliyatı kullanılarak eğitilen BERT, lisan anlamak ve işlemek için fevkalâde derecede güzel bir model. Hatta kimi durumlarda ortalama bir beşerden daha yeterli performans gösterebiliyor. Gücü ise etiketlenmemiş bilgi kümeleri yoluyla eğitilebilme ve en az değişiklikle uygulama yelpazesinin geneline değişiklikleri uygulayabilme imkanıdır.
Ayrıyeten BERT, birkaç farklı lisanı anlamak maksadıyla da kullanılabilir. Çeviri, otomatik söz tamamlama yahut arama sonuçlarının sıralaması üzere işlerde ince ayarlar yardımıyla kullanılabilir. Çok taraflılığı, karmaşık doğal lisanı anlayan yapay zekalar geliştiren kimseler için onu epey tanınan bir seçim haline getiriyor.
BERT teknolojisinin temelinde, dikkat tekniğini uygulayan tekrarcı hudut ağlarına alternatif olarak bir dönüştürme katmanı bulunuyor. Bu dönüştürme katmanı ise şu halde çalışıyor: Dikkati ondan evvel ve sonra gelen en alakalı sözlere odaklanmasıyla cümleyi çeşitli hallerde ayrıştırarak. Örneğin “dışarıda, pencerenin dışında vinç var” tabiri “göl kenarındaki klübeden” yahut “benim ofisimin” ile bitmesine bağlı olarak bir kuşu yahut inşaat alanını tanımlayabilmekte. Çift istikametli yahut istikametsiz kodlama diye bilinen metotlardan yararlanan BERT üzere yapay lisan modelleri duruma bağlı biçimde hangi mananın o anda geçerli olduğunu anlamak için bağlamlardan yararlanabilir.
Bugün dal bazlı lisan sürece vazifelerinde önder olan BioBERT (biyomedikal dokümanlar için) ve SciBERT (bilimsel yayınlar için) üzere birçok model BERT’e dayanıyor.
NVIDIA GPU’ların üstün paralel süreç yetenekleri ve Tensor Core mimarisi, model geliştiricilere bu stil karmaşık lisan modelleriyle çalışırken yüksek verimlilik ve ölçeklenebilirlik sağlıyor. Ayrıyeten BERT’in hem eğitimi hem de çıkarımı için kayıt belirleme performansını da uygun formda karşılıyor.
NVIDIA DGX SuperPOD sistemi kullanılan 340 milyon parametreye sahip BERT-Large modeli birkaç günlük tipik eğitim mühletine kıyasla bir saatte eğitilebiliyor. Lakin gerçek vakitli yapay zekalarda asıl hızlandırma mana çıkarımı içindir.
TensorRT yazılımını kullanan NVIDIA geliştiricileri 110 milyon parametreden oluşan BERT-Base modelini çıkarım için optimize etti. NVIDIA T4 grafik işlemcilerinde çalışan modeller “Stanford Question Answering Dataset/Stanford Soru Cevaplama Data Seti” kullanılarak test edildiğinde sırf 2.2 milisaniyede hesaplamayı yapıp yanıt vermeyi başardı. SQuAD olarak bilinen bu data kümesi, ekseriyetle bir yapay zeka modelinin manaya yeteneğini kıymetlendirmek gayesiyle tanınan bir kriterdir. Böylelikle NVIDIA geliştiricilerinin epey büyük bir şeyi başardığını söyleyebiliriz.
Birçok eş vakitli yapay zeka uygulaması için gecikme eşiği çoklukla 10 milisaniye kadardır. Ama çok yüksek seviyede optimize edilen merkezi işlemci kodu (CPU) bile 40 milisaniyeden daha uzun süren bir süreç müddetiyle sonuçlanır. Çıkarım mühletini yalnızca birkaç milisaniyeye düşürerek üretim etabında BERT’i birinci sefer kullanmak bir oldukça pratiktir.
Ayrıyeten bütün NVIDIA lisan sürece yardımcıları yalnızca BERT ile bitmiyor. GPT-2, XLNet ve RoBERTa üzere başka büyük dönüştürme tabanlı doğal lisan sürece modellerini hızlandırmak gayesiyle tıpkı metotlar kullanılabilir.
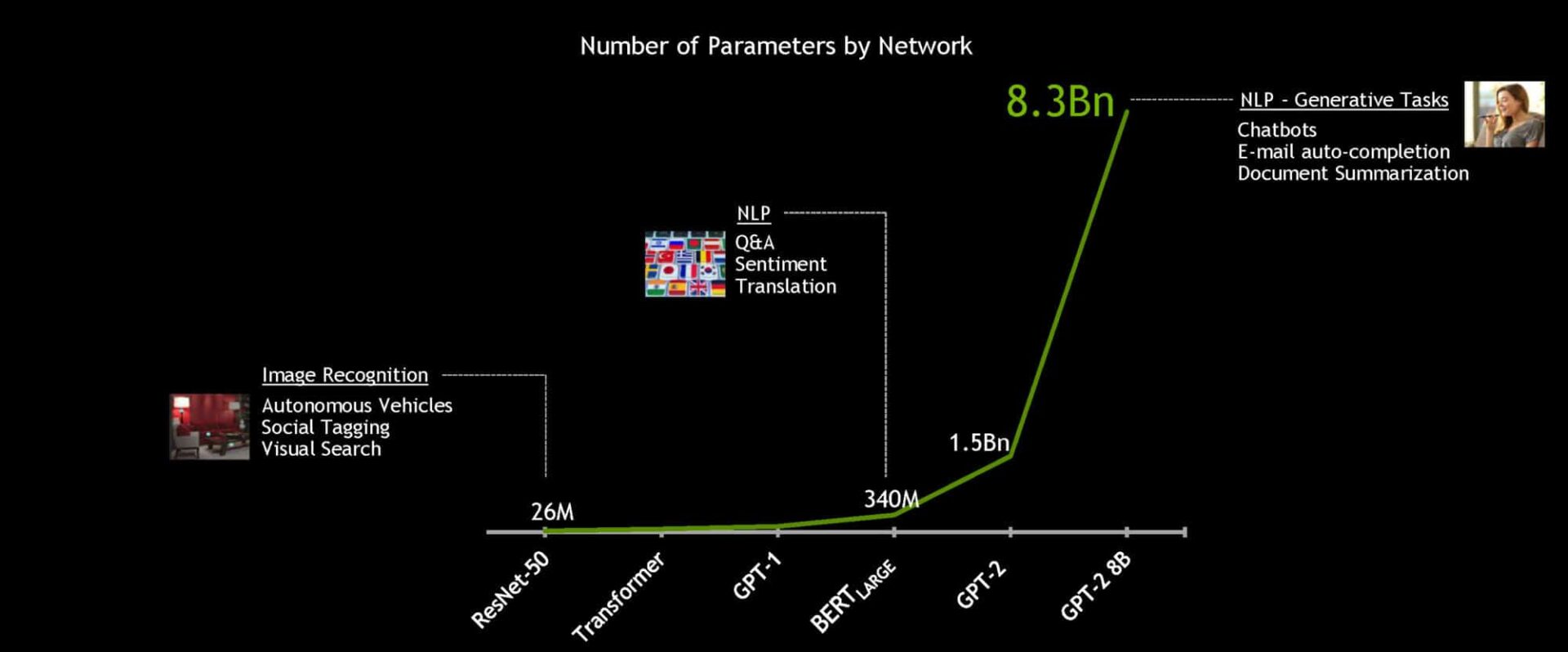
Gerçek manada yapay konuşma zekaları amaca ulaşmak için geliştirilmeye devam ediliyor, lisan modelleri büyüyor. Gelecekte yapay zeka modelleri bugünkilerle kıyaslandığında kat kat daha büyük olacak. NVIDIA bu nedenle şu ana kadarki en büyük dönüştürme tabanlı yapay zekayı geliştirip açık kaynak dünyasına sundu: BERT-Large’dan 24 kat daha büyük olan 8.2 milyar parametreye sahip lisan sürece modeli olan GPT-2 8B. Bu inanılmaz bir şey.
NVIDIA Derin Öğrenme Enstitüsü metin sınıflandırma, evrak kategorize etme üzere birtakım misyonları yerine getirmek için dönüştürme tabanlı doğal lisan sürece modelleri ve onları oluşturmaya yönelik kimi temel araçlar/teknikler hakkında eğitmen liderliğinde uygulamalı eğitimler sunuyor.
Uzmanlar tarafından hazırlanan 8 saatlik kapsamlı atölye çalışması iştirakçilere aşağıdakileri yapabilmede çeşitli talimatlarala yardımcı oluyor:
- Word2Vec ve yinelenen hudut ağları kullanan yerleştirme tekniklerinden tutun, Transformer tabanlı modellere kadar NLP vazifelerinde söz yerleştirmenin nasıl süratlice geliştiğini anlamak.
- Dönüştürücü mimarisine dair birtakım spesifikasyonların, bilhassa de kendi kendine dikakt yeteneğinin RNN’ler olmadan lisan modelleri oluşturmak emeliyle nasıl kullanıldığını görmek.
- Uygun NLP sonuçları almak için BERT, Megatron ve öteki varyantlardaki dönüştürme modellerini geliştirmek emeliyle self-supervision teknolojilerini kullanmak.
- Soru yanıtlama ve NER, metin sınıflandırması üzere birçok vazifesi çözmek emeliyle evvelden eğitilen çağdaş NLP modellerinden yararlanmak.
- Çıkarımsal zorlukları yönetmek ve gerçek uygulamalar için güzelleştirilmiş modelleri dağıtmak.
Şayet diyalog tabanlı yapay zekalar ve yapay zeka alanında NVIDIA tarafından yapılmış öbür çalışmaları merak ediyorsanız NVIDIA Geliştirici Blogu’nu okuyabilirsiniz.



